Configuration
Welcome to the Kairos configuration reference page. This page provides details on the fields available in the YAML file used for installing Kairos, a Linux distribution focused on running Kubernetes. This file, written in cloud-config format, allows you to enable Kairos features, configure k3s, and set various other options.
The structure of the configuration file is as follows:
#cloud-config
# Additional system users
users:
- name: "kairos"
passwd: "kairos"
lock_passwd: true
groups: [ "admin" ]
# ssh_authorized_keys:
# - github:mudler
# enable debug logging
debug: true
# Logs configuration for collecting diagnostic information
# Note: The following are examples of additional services and files to collect.
# The system already includes comprehensive defaults for Kairos services.
logs:
# Additional systemd journal services to collect logs from
journal:
- "my-custom-service"
- "my-app"
# Additional log files to collect (supports glob patterns)
files:
- "/var/log/myapp/*.log"
- "/var/log/custom/*.log"
# Additional paths for look for cloud-init files
cloud-init-paths:
- "/some/path"
# fail on cloud-init errors, defaults to false
strict: false
# The install block is to drive automatic installations without user interaction.
install:
# Device for automated installs
# This can be either a full device path (so /dev/sda) or you can use the udev facility to identify the disk by UUID, path, label, diskseq or id (/dev/disk/by-{uuid,label,path,diskseq})
# Note that to use a disk by UUID or label, it has first to have that added from userspace, for example with `mkfs.ext4 -L LABEL -U UUID /dev/sda` otherwise disks dont come with UUID/label if they are empty
device: "/dev/sda"
# Reboot after installation
reboot: true
# Power off after installation
poweroff: true
# Set to true when installing without Pairing
auto: true
# Override the grub entry name
grub-entry-name: Kairos
# partitions setup
# setting a partition size key to 0 means that the partition will take over the rest of the free space on the disk
# after creating the rest of the partitions
# by default the persistent partition has a value of 0
# if you want any of the extra partitions to fill the rest of the space, you will need to set the persistent partition
# size to a different value, for example
# partitions:
# persistent:
# size: 300
# default partitions
# only 'oem', 'recovery', 'state' and 'persistent' objects allowed
# Only size and fs should be changed here
# size in MiB
partitions:
oem:
size: 60
fs: ext4
recovery:
size: 4096
fs: ext4
# note: This can also be set with dot notation like the following examples for a more condensed view:
# partitions.oem.size: 60
# partitions.oem.fs: ext4
# partitions.recovery.size: 4096
# partitions.recovery.fs: ext4
# extra partitions to create during install
# only size, label and fs are used
# name is used for the partition label, but it's not really used during the kairos lifecycle. No spaces allowed.
# if no fs is given the partition will be created but not formatted
# These partitions are not automounted only created and formatted
extra-partitions:
- name: myPartition
size: 100
fs: ext4
label: ONE_PARTITION
- name: myOtherPartition
size: 200
fs: ext4
label: TWO_PARTITION
# no-format: true skips any disk partitioning and formatting
# If set to true installation procedure will error out if expected
# partitions are not already present within the disk.
no-format: false
# if no-format is used and Kairos is running over an existing deployment
# force can be used to force installation.
force: false
# Creates these dirs in the rootfs during installation. As the rootfs is RO from boot, sometimes we find that we
# some applications want to write to non-standard paths like /data
# If that dir is not already in the rootfs it makes it difficult to create that path on an RO system
# This allows to create some extra paths in the rootfs that then we count use for mounting or binding via
# the cloud-config stages
extra-dirs-rootfs:
- /data
- /src
# Override image sizes for active/passive/recovery
# Note that the active+passive images are stored in the state partition and
# the recovery in the recovery partition, so they should be big enough to accommodate te images sizes set below
# size in MiB
system:
size: 4096
# Use a different source for the installation of active system
source: "oci:.."
passive:
size: 4096
recovery-system:
size: 5000
# Use a different source for the installation of recovery system
source: "oci:.."
# note: This can also be set with dot notation like the following examples for a more condensed view:
# system.size: 4096
# passive.size: 4096
# recovery-system.size: 5000
# Add bundles in runtime
bundles:
- ...
# Set grub options
grub_options:
# additional Kernel option cmdline to apply
extra_cmdline: "config_url=http://"
# Same, just for active
extra_active_cmdline: ""
# Same, just for passive
extra_passive_cmdline: ""
# Change GRUB menu entry
default_menu_entry: ""
# Environmental variable to set to the installer calls
env:
- foo=bar
# custom user mounts
# bind mounts, can be read and modified, changes persist reboots
bind_mounts:
- /mnt/bind1
- /mnt/bind2
# ephemeral mounts, can be read and modified, changed are discarded at reboot
ephemeral_mounts:
# The reset block configures what happens when reset is called
reset:
# Reboot after reset
reboot: true
# Power off after reset
poweroff: true
# System Image (maps to Active), sets the source to reset to
system:
source: "oci:.."
# Override the grub entry name
grub-entry-name: Kairos
# if set to true it will format persistent partitions ('oem 'and 'persistent')
reset-persistent: true
reset-oem: false
# Creates these dirs in the rootfs during reset. As the rootfs is RO from boot, sometimes we find that we
# some applications want to write to non-standard paths like /data
# If that dir is not already in the rootfs it makes it difficult to create that path on an RO system
# This allows to create some extra paths in the rootfs that then we count use for mounting or binding via
# the cloud-config stages
extra-dirs-rootfs:
- /data
- /src
# The upgrade block configures what happens when upgrade is called
upgrade:
# Reboot after upgrade
reboot: true
# Power off after upgrade
poweroff: true
# Override the grub entry name
grub-entry-name: Kairos
# if set to true upgrade command will upgrade recovery system instead
# of main active system
recovery: false
# Override image sizes for active/recovery
# Note that the active+passive images are stored in the state partition and
# the recovery in the recovery partition, so they should be big enough to accommodate te images sizes set below
# size in MiB
# During upgrade only the active or recovery image cna be resized as those are the ones that contain the upgrade
# passive image is the current system, and that its untouched during the upgrade
# System Image (maps to Active)
system:
source: "oci:.."
size: 4096
# Recovery System Image (maps to Recovery)
recovery-system:
source: "oci:.."
size: 5000
# Creates these dirs in the rootfs during upgrade. As the rootfs is RO from boot, sometimes we find that we
# some applications want to write to non-standard paths like /data
# If that dir is not already in the rootfs it makes it difficult to create that path on an RO system
# This allows to create some extra paths in the rootfs that then we count use for mounting or binding via
# the cloud-config stages
extra-dirs-rootfs:
- /data
- /src
k3s:
# Additional env/args for k3s server instances
env:
K3S_RESOLV_CONF: ""
K3S_DATASTORE_ENDPOINT: "mysql://username:password@tcp(hostname:3306)/database-name"
args:
- --node-label ""
- --data-dir ""
# Enabling below it replaces args/env entirely
# replace_env: true
# replace_args: true
k3s-agent:
# Additional env/args for k3s agent instances
env:
K3S_NODE_NAME: "foo"
args:
- --private-registry "..."
# Enabling below it replaces args/env entirely
# replace_env: true
# replace_args: true
# The p2p block enables the p2p full-mesh functionalities.
# To disable, don't specify one.
p2p:
# Manually set node role. Available: master, worker. Defaults auto (none). This is available
role: "master"
# User defined network-id. Can be used to have multiple clusters in the same network
network_id: "dev"
# Enable embedded DNS See also: https://mudler.github.io/edgevpn/docs/concepts/overview/dns/
dns: true
# Disabling DHT makes co-ordination to discover nodes only in the local network
disable_dht: true #Enabled by default
# Configures a VPN for the cluster nodes
vpn:
create: false # defaults to true
use: false # defaults to true
env:
# EdgeVPN environment options
DHCP: "true"
# Disable DHT (for airgap)
EDGEVPNDHT: "false"
EDGEVPNMAXCONNS: "200"
# If DHCP is false, it's required to be given a specific node IP. Can be arbitrary
ADDRESS: "10.2.0.30/24"
# See all EDGEVPN options:
# - https://github.com/mudler/edgevpn/blob/master/cmd/util.go#L33
# - https://github.com/mudler/edgevpn/blob/master/cmd/main.go#L48
# Automatic cluster deployment configuration
auto:
# Enables Automatic node configuration (self-coordination)
# for role assignment
enable: true
# HA enables automatic HA roles assignment.
# A master cluster init is always required,
# Any additional master_node is configured as part of the
# HA control plane.
# If auto is disabled, HA has no effect.
ha:
# Enables HA control-plane
enable: true
# Number of HA additional master nodes.
# A master node is always required for creating the cluster and is implied.
# The setting below adds 2 additional master nodes, for a total of 3.
master_nodes: 2
# Use an External database for the HA control plane
external_db: "external-db-string"
# network_token is the shared secret used by the nodes to co-ordinate with p2p
network_token: "YOUR_TOKEN_GOES_HERE"
## Sets the Elastic IP used in KubeVIP. Only valid with p2p
kubevip:
eip: "192.168.1.110"
# Specify a manifest URL for KubeVIP. Empty uses default
manifest_url: ""
# Enables KubeVIP
enable: true
# Specifies a KubeVIP Interface
interface: "ens18"
# Additional cloud init syntax can be used here.
# See `stages` below.
stages:
network:
- name: "Setup users"
authorized_keys:
kairos:
- github:mudler
# Standard cloud-init syntax, see: https://github.com/mudler/yip/tree/e688612df3b6f24dba8102f63a76e48db49606b2#compatibility-with-cloud-init-format
growpart:
devices: ['/']
runcmd:
- foo
hostname: "bar"
write_files:
- encoding: b64
content: CiMgVGhpcyBmaWxlIGNvbnRyb2xzIHRoZSBzdGF0ZSBvZiBTRUxpbnV4
path: /foo/bar
permissions: "0644"
owner: "bar"
The p2p block is used to enable the p2p full-mesh functionalities of Kairos. If you do not want to use these functionalities, simply don't specify a kairos block in your configuration file.
Inside the p2p block, you can specify the network_token field, which is used to establish the p2p full meshed network. If you do not want to use the full-mesh functionalities, don't specify a network_token value.
The role field allows you to manually set the node role for your Kairos installation. The available options are master and worker, and the default value is auto (which means no role is set).
The network_id field allows you to set a user-defined network ID, which can be used to have multiple Kairos clusters on the same network.
Finally, the dns field allows you to enable embedded DNS for Kairos. For more information on DNS in Kairos, see the link provided in the YAML code above.
That's a brief overview of the structure and fields available in the Kairos configuration file. For more detailed information on how to use these fields, see the examples and explanations provided in the sections below.
Syntax
Kairos supports a portion of the standard cloud-init syntax, and the extended syntax which is based on yip.
Examples using the extended notation for running K3s as agent or server can be found in the examples directory of the Kairos repository.
Here's an example that shows how to set up DNS at the boot stage using the extended syntax:
#cloud-config
stages:
boot:
- name: "DNS settings"
dns:
path: /etc/resolv.conf
nameservers:
- 8.8.8.8
Kairos does not use cloud-init. yip was created with the goal of being distro agnostic, and does not use Bash at all (with the exception of systemd configurations, which are assumed to be available). This makes it possible to run yip on minimal Linux distros that have been built from scratch.
The rationale behind using yip instead of cloud-init is that it allows Kairos to have very minimal requirements. The cloud-init implementation has dependencies, while yip does not, which keeps the dependency tree small. There is also a CoreOS implementation of cloud-init, but it makes assumptions about the layout of the system that are not always applicable to Kairos, making it less portable.
The extended syntax can also be used to pass commands through Kernel boot parameters. See the examples below for more details.
Test your cloud configs
Writing YAML files can be a tedious process, and it's easy to make syntax or indentation errors. To make sure your configuration is correct, you can use the cloud-init commands to test your YAML files locally in a container.
Here's an example of how to test your configurations on the initramfs stage using a Docker container:
# List the YAML files in your current directory
$ ls -liah
total 4,0K
9935 drwxr-xr-x. 2 itxaka itxaka 60 may 17 11:21 .
1 drwxrwxrwt. 31 root root 900 may 17 11:28 ..
9939 -rw-r--r--. 1 itxaka itxaka 59 may 17 11:21 00_test.yaml
$ cat 00_test.yaml
stages:
initramfs:
- commands:
- echo "hello!"
# Run the cloud-init command on your YAML files in a Docker container
$ docker run -ti -v $PWD:/test --entrypoint /usr/bin/kairos-agent --rm quay.io/kairos/hadron:v0.0.4-core-amd64-generic-v4.0.1 run-stage --cloud-init-paths /test initramfs
# Output from the run-stage command
INFO[2023-05-17T11:32:09+02:00] kairos-agent version 0.0.0
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs.before
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs.before'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs
INFO[2023-05-17T11:32:09+02:00] Processing stage step ''. ( commands: 1, files: 0, ... )
INFO[2023-05-17T11:32:09+02:00] Command output: hello!
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs.after
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs.after'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs.before
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs.before'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs.after
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs.after'
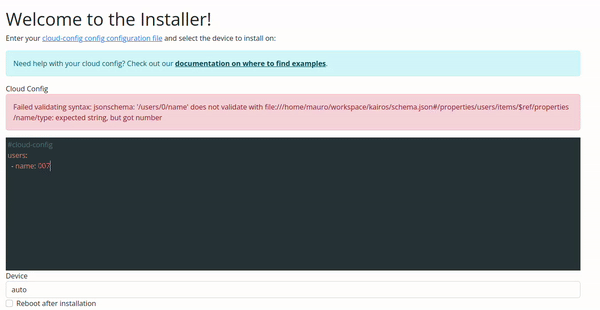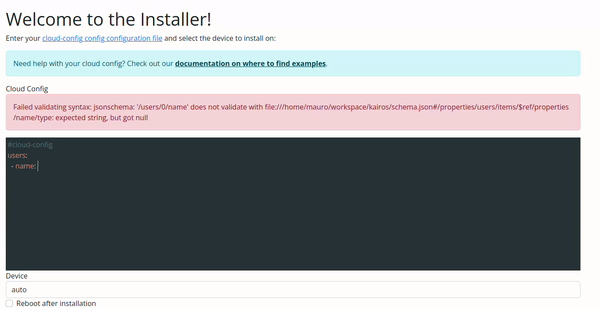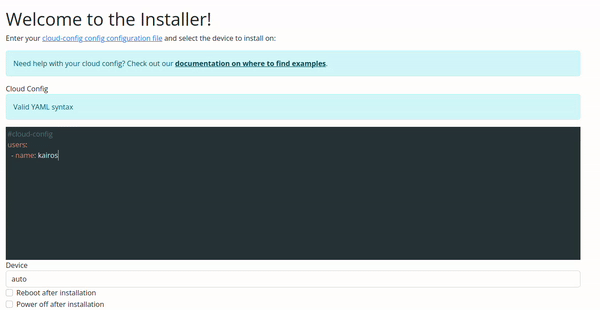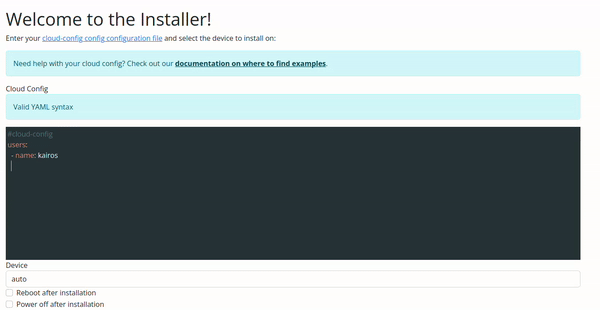
Validate Your Cloud Config
Validation of configuration is available on Kairos v1.6.0-rc1 and later. If you're interested in the validation rules or want to build a tool based on it, you can access them online via https://kairos.io/RELEASE/cloud-config.json e.g. v1.6.0 cloud-config.json
You have two options to validate your Cloud Config, one is with the Kairos command line, and the other with the Web UI.
Configuration Validation via the Kairos Command Line
To validate a configuration using the command line, we have introduced the validate command. As an argument you need to pass a URL or local file to be validated, e.g.:
If you had the following cloud-config.yaml in the current working directory
#cloud-config
users:
- name: 007
You could validate it as follows
kairos validate ./cloud-config.yaml
jsonschema: '/users/0/name' does not validate with file:///home/mauro/workspace/kairos/schema.json#/properties/users/items/$ref/properties/name/type: expected string, but got number
Configuration Validation via Web UI
The validation in the Web UI is automatic, all you need to do is copy/paste or type your configuration on the input.
Using templates
Fields in the Kairos cloud-init configuration can be templated, which allows for dynamic configuration. Node information is retrieved using the sysinfo library, and can be templated in the commands, file, and entity fields.
Here's an example of how you can use templating in your Kairos configuration:
#cloud-config
stages:
foo:
- name: "echo"
commands:
- echo "{{.Values.node.hostname}}"
In addition to standard templating, sprig functions are also available for use in your Kairos configuration.
Automatic Hostname at scale
You can also use templating to automatically generate hostnames for a set of machines. For example, if you have a single cloud-init file that you want to use for multiple machines, you can use the machine ID (which is generated for each host) to automatically set the hostname for each machine.
Here's an example of how you can do this:
#cloud-config
stages:
initramfs:
- name: "Setup hostname"
hostname: "node-{{ trunc 4 .MachineID }}"
This will set the hostname for each machine based on the first 4 characters of the machine ID. For example, if the machine ID for a particular machine is abcdef123456, the hostname for that machine will be set to node-abcd.
Grub options
The install.grub_options field in the Kairos configuration file allows you to set key/value pairs for GRUB options that will be set in the GRUB environment after installation.
Here's an example of how you can use this field to set the panic=0 boot argument:
#cloud-config
install:
grub_options:
extra_cmdline: "panic=0"
The table below lists all the available options for the install.grub_options field:
| Variable | Description |
|---|---|
| next_entry | Set the next reboot entry |
| saved_entry | Set the default boot entry |
| default_menu_entry | Set the name entries on the GRUB menu |
| extra_active_cmdline | Set additional boot commands when booting into active |
| extra_passive_cmdline | Set additional boot commands when booting into passive |
| extra_recovery_cmdline | Set additional boot commands when booting into recovery |
| extra_cmdline | Set additional boot commands for all entries |
| default_fallback | Sets default fallback logic |
The order of the cmdline parameters is as follows:
- Existing cmdline parameters, shipped with Kairos by default and non-modifiable
2.
extra_cmdline3.extra_active_cmdlineorextra_passive_cmdlineorextra_recovery_cmdlinedepending on the entry being booted
Note that usually parameters for dracut and such are overridable, as they use the latest specified value in the cmdline.
For example, the rd.neednet=0 parameter is shipped with Kairos by default, but if you set rd.neednet=1 in extra_cmdline, it will override the default value and enable networking during the initramfs stage.
Also note that the grub_options for cmdline are only applied during installation. Changing them after installation won't have any effect.
If you want to change the GRUB options after installation, you can do so by setting those values under the /oem/grubenv file as follows:
grub2-editenv /oem/grubenv set extra_cmdline="rd.neednet=1"
As a final note, just a reminder that during GRUB menu selection, you can press e to edit the cmdline for that boot only, which is useful for testing purposes. That allows to test extra cmdline parameters during a single boot before making them permanent.
Kubernetes manifests
The k3s distribution of Kubernetes allows you to automatically deploy Helm charts or Kubernetes resources after deployment.
Here's an example of how you can use the k3s configuration file to deploy Fleet out of the box:
name: "Deploy fleet out of the box"
stages:
boot:
- name: "Copy fleet deployment files"
files:
- path: /var/lib/rancher/k3s/server/manifests/fleet-config.yaml
content: |
apiVersion: v1
kind: Namespace
metadata:
name: cattle-system
---
apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata:
name: fleet-crd
namespace: cattle-system
spec:
chart: https://github.com/rancher/fleet/releases/download/v0.3.8/fleet-crd-0.3.8.tgz
---
apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata:
name: fleet
namespace: cattle-system
spec:
chart: https://github.com/rancher/fleet/releases/download/v0.3.8/fleet-0.3.8.tgz
This configuration will automatically deploy the Fleet Helm chart in the cattle-system namespace after the deployment of k3s using the extended syntax.
Kernel boot parameters
All the configurations can be issued via Kernel boot parameters, for instance, consider to add an user from the boot menu:
stages.boot[0].authorized_keys.root[0]=github:mudler
Or to either load a config url from network:
config_url=http://...
Usually secret gists are used to share such config files.
Additional users
Kairos comes with the kairos user pre-configured, however, it is possible to configure additional users to the system via the cloud-init config mechanism
Add a user
Consider the following example cloud-config, containing the default kairos user (which always has sudo access) and adds the testuser user to the system with admin access:
#cloud-config
install:
device: /dev/sda
k3s:
enabled: true
users:
- name: "kairos"
passwd: "kairos"
ssh_authorized_keys:
- github:mudler
- name: "testuser"
passwd: "testuser"
ssh_authorized_keys:
- github:mudler
groups:
- "admin"
The above cloud config will be respected on every boot. Adding a user in the config at any point will be reflected on the next boot.
The top level users: key is mapped automatically to a boot stage.
For this reason, the above snippet is equivalent to adding the user by explicitly defining the stage. E.g. by creating this file inside /oem:
stages:
initramfs:
- name: "Set user and password"
users:
testuser:
groups:
- "admin"
passwd: "mypassword"
shell: /bin/bash
homedir: "/home/testuser"
This configuration can be either manually copied over, or can be propagated also via Kubernetes using the system upgrade controller. See the after-install section for an example.
❯ ssh testuser@192.168.1.238
testuser@192.168.1.238's password:
Welcome to kairos!
Refer to https://kairos.io for documentation.
localhost:~$ sudo su -
localhost:~# whoami
root
localhost:~# exit
localhost:~$ whoami
testuser
localhost:~$
Provider configs
Providers are small binaries that can be used to extend the capabilities of Kairos. They are typically used to provide additional functionality or to integrate with external systems like k3s, k0s, rke2, or other Kubernetes distributions or even to provide additional functionality like p2p networking.
This allows to use the same configuration file to install different Kubernetes distributions or to enable additional features like p2p networking.
Below is a list of the configurations available for the current providers.
Note that there is currently more providers available but some are community maintained. You should refer to the provider documentation for more information on how to use them.
- k3s
- k3s-agent
- k0s
- k0s-worker
- kubevip
- kubeadm
- p2p
| Key | Description |
|---|---|
k3s.enabled | Enables the k3s server instance. Accepted: true, false. |
k3s.env | Additional environment variables for the k3s server instance. |
k3s.args | Additional arguments for the k3s server instance. |
k3s.replace_env | Replaces all environment variables otherwise passed to k3s by Kairos with those supplied here. Make sure you pass all the environment variables you need. |
k3s.replace_args | Replaces all arguments otherwise passed to k3s by Kairos with those supplied here. Make sure you pass all the arguments you need. |
k3s.embedded_registry | Enables the embedded registry in k3s. Accepted: true, false. |
WARNING: The K3s args are only applied when the K3s service is created, which is during installation. Changing the args key after installation won't have any effect.
In order to override an existing k3s install arguments, you need to override the default service ones.
For Alpine services, the trick is to write via cloud config the /etc/rancher/k3s/k3s.env file to set the proper command_args like so:
stages:
initramfs:
- name: "Override k3s environment"
environment_file: /etc/rancher/k3s/k3s.env
environment:
command_args: server --verbose
For systemd services, the usual override methods from systemd itself are available to override any services config, so we can lean on the yip plugin for systemd:
stages:
initramfs:
- name: "Expand k3s modules load"
systemctl:
overrides:
- service: k3s.service
content: |
[Service]
ExecStartPre=-/sbin/modprobe nfs
| Key | Description |
|---|---|
k3s-agent.enabled | Enables the k3s agent instance. Accepted: true, false. |
k3s-agent.env | Additional environment variables for the k3s server instance. |
k3s-agent.args | Additional arguments for the k3s server instance. |
k3s-agent.replace_env | Replaces all environment variables otherwise passed to k3s by Kairos with those supplied here. Make sure you pass all the environment variables you need. |
k3s-agent.replace_args | Replaces all arguments otherwise passed to k3s by Kairos with those supplied here. Make sure you pass all the arguments you need. |
k3s-agent.embedded_registry | Enables the embedded registry in k3s. Accepted: true, false. |
| Key | Description |
|---|---|
k0s.enabled | Enables the k0s server instance. Accepted: true, false. |
k0s.env | Additional environment variables for the k0s server instance. |
k0s.args | Additional arguments for the k0s server instance. |
k0s.replace_env | Replaces all environment variables otherwise passed to k0s by Kairos with those supplied here. Make sure you pass all the environment variables you need. |
k0s.replace_args | Replaces all arguments otherwise passed to k3s by Kairos with those supplied here. Make sure you pass all the arguments you need. |
| Key | Description |
|---|---|
k0s-worker.enabled | Enables the k0s worker instance. Accepted: true, false. |
k0s-worker.env | Additional environment variables for the k0s worker instance. |
k0s-worker.args | Additional arguments for the k0s worker instance. |
k0s-worker.replace_env | Replaces all environment variables otherwise passed to k0s by Kairos with those supplied here. Make sure you pass all the environment variables you need. |
k0s-worker.replace_args | Replaces all arguments otherwise passed to k0s by Kairos with those supplied here. Make sure you pass all the arguments you need. |
| Key | Description |
|---|---|
kubevip.enable | Enables kubevip. Accepted: true, false. |
kubevip.eip | VIP address to use |
kubevip.manifest_url | Download and use the manifest from that url. You can see the default used otherwise here |
kubevip.interface | Interface to use for the Kubevip EIP to attach to |
kubevip.static_pod | Use a pod deployment for Kubevip instead of a daemonset. Accepted: true, false |
kubevip.version | Set the specific Kubevip version to use |
| Key | Description |
|---|---|
cluster.cluster_token | Unique string that can be used to distinguish different clusters on networks with multiple clusters. |
cluster.control_plane_host | Host that all nodes can resolve and use for node registration. |
cluster.role | The role of the node in the cluster. Accepted values are master, worker, and none. Defaults to none. |
cluster.config | The configuration for the cluster. |
cluster.env | List of environment variables to be set on the cluster. |
cluster.local_images_path | Path to the local archive images to import. |
As P2P is a very complex topic, we have a dedicated P2P documentation page that explains how to use it with deep details.
Stages
The stages key is a map that allows to execute blocks of cloud-init directives during the lifecycle of the node stages.
A full example of a stage is the following:
#cloud-config
stages:
# "boot" is the stage
boot:
- systemd_firstboot:
keymap: us
- files:
- path: /tmp/bar
content: |
test
permissions: 0777
owner: 1000
group: 100
if: "[ ! -e /tmp/bar ]"
- files:
- path: /tmp/foo
content: |
test
permissions: 0777
owner: 1000
group: 100
commands:
- echo "test"
modules:
- nvidia
environment:
FOO: "bar"
systctl:
debug.exception-trace: "0"
hostname: "foo"
systemctl:
enable:
- foo
disable:
- bar
start:
- baz
mask:
- foobar
authorized_keys:
user:
- "github:mudler"
- "ssh-rsa ...."
dns:
path: /etc/resolv.conf
nameservers:
- 8.8.8.8
ensure_entities:
- path: /etc/passwd
entity: |
kind: "user"
username: "foo"
password: "pass"
uid: 0
gid: 0
info: "Foo!"
homedir: "/home/foo"
shell: "/bin/bash"
delete_entities:
- path: /etc/passwd
entity: |
kind: "user"
username: "foo"
password: "pass"
uid: 0
gid: 0
info: "Foo!"
homedir: "/home/foo"
shell: "/bin/bash"
datasource:
path: "/usr/local/etc"
providers:
- "digitalocean"
- "aws"
- "gcp"
Note multiple stages can be specified, to execute blocks into different stages, consider:
#cloud-config
stages:
boot:
- commands:
- echo "hello from the boot stage"
initramfs:
- commands:
- echo "hello from the boot stage"
- commands:
- echo "so much wow, /foo/bar bar exists!"
if: "[ -e /foo/bar ]"
Logs Configuration
The logs configuration allows you to specify additional systemd journal services and log files to collect when using the kairos-agent logs command. This is useful for debugging and issue reporting.
The system already includes comprehensive defaults for Kairos services and common log files. You only need to specify additional services or files that are not covered by the defaults.
Default Services
The following services are automatically included:
kairos-agent,kairos-installer,kairos-webuicos-setup-boot,cos-setup-fs,cos-setup-network,cos-setup-reconcilek3s,k3s-agent,k0scontroller,k0sworker
Default Files
The following log file patterns are automatically included:
/var/log/kairos/*.log/var/log/*.log/run/immucore/*.log
journal
A list of additional systemd journal service names to collect logs from. Only specify services that are not already included in the defaults.
files
A list of additional log file paths to collect. Supports glob patterns for matching multiple files. Only specify files that are not already covered by the default patterns.
Example configuration for adding custom services and files:
#cloud-config
logs:
journal:
- "my-custom-service"
- "my-app"
files:
- "/var/log/myapp/*.log"
- "/var/log/custom/*.log"
Below you can find a list of all the supported fields. Mind to replace with the appropriate stage you want to hook into.
Filtering stages by node hostname
Stages can be filtered using the node key with a hostname value:
#cloud-config
stages:
foo:
- name: "echo"
commands:
- echo hello
node: "the_node_hostname_here" # Node hostname
Filtering stages with if statement
Stages can be skipped based on if statements:
#cloud-config
stages:
foo:
- name: "echo"
commands:
- echo hello
if: "cat /proc/cmdline | grep debug"
name: "Test yip!"
The expression inside the if will be evaluated in bash and, if specified, the stage gets executed only if the condition returns successfully (exit 0).
name
A description of the stage step. Used only when printing output to console.
node
If defined, the node hostname where this stage has to run, otherwise it skips the execution. The node can also be a regexp in the Golang format.
#cloud-config
stages:
boot:
- name: "Setup logging"
node: "bastion"
Modules
For each stage, a number of modules are available, that implement various useful functions. Read more about them in this page: Stage modules
Running commands on different shells
By default, all commands are executed in the sh shell. However, it is possible to run commands in a different shell by prefixing the command with the executable.
For example, to run a command in the bash shell, you can use the following syntax:
#cloud-config
stages:
boot.after:
- name: "do something"
commands:
- bash /path/to/script.sh