Configuration
Welcome to the Kairos configuration reference page. This page provides details on the fields available in the YAML file used for installing Kairos, a Linux distribution focused on running Kubernetes. This file, written in cloud-config format, allows you to enable Kairos features, configure k3s, and set various other options.
The structure of the configuration file is as follows:
#cloud-config
# Additional system users
users:
- name: "kairos"
passwd: "kairos"
lock_passwd: true
groups: "admin"
ssh_authorized_keys:
# - github:mudler
# enable debug logging
debug: true
# Additional paths for look for cloud-init files
cloud-init-paths:
- "/some/path"
# fail on cloud-init errors, defaults to false
strict: false
# The install block is to drive automatic installations without user interaction.
install:
# Device for automated installs
device: "/dev/sda"
# Reboot after installation
reboot: true
# Power off after installation
poweroff: true
# Set to true when installing without Pairing
auto: true
# Override the grub entry name
grub-entry-name: Kairos
# partitions setup
# setting a partition size key to 0 means that the partition will take over the rest of the free space on the disk
# after creating the rest of the partitions
# by default the persistent partition has a value of 0
# if you want any of the extra partitions to fill the rest of the space, you will need to set the persistent partition
# size to a different value, for example
# partitions:
# persistent:
# size: 300
# default partitions
# only 'oem', 'recovery', 'state' and 'persistent' objects allowed
# Only size and fs should be changed here
# size in MiB
partitions:
oem:
size: 60
fs: ext4
recovery:
size: 4096
fs: ext4
# note: This can also be set with dot notation like the following examples for a more condensed view:
# partitions.oem.size: 60
# partitions.oem.fs: ext4
# partitions.recovery.size: 4096
# partitions.recovery.fs: ext4
# extra partitions to create during install
# only size, label and fs are used
# name is used for the partition label, but it's not really used during the kairos lifecycle. No spaces allowed.
# if no fs is given the partition will be created but not formatted
# These partitions are not automounted only created and formatted
extra-partitions:
- Name: myPartition
size: 100
fs: ext4
label: ONE_PARTITION
- Name: myOtherPartition
size: 200
fs: ext4
label: TWO_PARTITION
# no-format: true skips any disk partitioning and formatting
# If set to true installation procedure will error out if expected
# partitions are not already present within the disk.
no-format: false
# if no-format is used and elemental is running over an existing deployment
# force can be used to force installation.
force: false
# Creates these dirs in the rootfs during installation. As the rootfs is RO from boot, sometimes we find that we
# some applications want to write to non-standard paths like /data
# If that dir is not already in the rootfs it makes it difficult to create that path on an RO system
# This allows to create some extra paths in the rootfs that then we count use for mounting or binding via
# the cloud-config stages
extra-dirs-rootfs:
- /data
- /src
# Override image sizes for active/passive/recovery
# Note that the active+passive images are stored in the state partition and
# the recovery in the recovery partition, so they should be big enough to accommodate te images sizes set below
# size in MiB
system:
size: 4096
passive:
size: 4096
recovery-system:
size: 5000
# note: This can also be set with dot notation like the following examples for a more condensed view:
# system.size: 4096
# passive.size: 4096
# recovery-system.size: 5000
# Use a different container image for the installation
image: "docker:.."
# Add bundles in runtime
bundles:
- ...
# Set grub options
grub_options:
# additional Kernel option cmdline to apply
extra_cmdline: "config_url=http://"
# Same, just for active
extra_active_cmdline: ""
# Same, just for passive
extra_passive_cmdline: ""
# Change GRUB menu entry
default_menu_entry: ""
# Environmental variable to set to the installer calls
env:
- foo=bar
# custom user mounts
# bind mounts, can be read and modified, changes persist reboots
bind_mounts:
- /mnt/bind1
- /mnt/bind2
# ephemeral mounts, can be read and modified, changed are discarded at reboot
ephemeral_mounts:
# The reset block configures what happens when reset is called
reset:
# Reboot after reset
reboot: true
# Power off after reset
poweroff: true
# Override the grub entry name
grub-entry-name: Kairos
# if set to true it will format persistent partitions ('oem 'and 'persistent')
reset-persistent: true
reset-oem: false
# Creates these dirs in the rootfs during reset. As the rootfs is RO from boot, sometimes we find that we
# some applications want to write to non-standard paths like /data
# If that dir is not already in the rootfs it makes it difficult to create that path on an RO system
# This allows to create some extra paths in the rootfs that then we count use for mounting or binding via
# the cloud-config stages
extra-dirs-rootfs:
- /data
- /src
# The upgrade block configures what happens when upgrade is called
upgrade:
# Reboot after upgrade
reboot: true
# Power off after upgrade
poweroff: true
# Override the grub entry name
grub-entry-name: Kairos
# if set to true upgrade command will upgrade recovery system instead
# of main active system
recovery: false
# Override image sizes for active/recovery
# Note that the active+passive images are stored in the state partition and
# the recovery in the recovery partition, so they should be big enough to accommodate te images sizes set below
# size in MiB
# During upgrade only the active or recovery image cna be resized as those are the ones that contain the upgrade
# passive image is the current system, and that its untouched during the upgrade
system:
size: 4096
recovery-system:
size: 5000
# Creates these dirs in the rootfs during upgrade. As the rootfs is RO from boot, sometimes we find that we
# some applications want to write to non-standard paths like /data
# If that dir is not already in the rootfs it makes it difficult to create that path on an RO system
# This allows to create some extra paths in the rootfs that then we count use for mounting or binding via
# the cloud-config stages
extra-dirs-rootfs:
- /data
- /src
k3s:
# Additional env/args for k3s server instances
env:
K3S_RESOLV_CONF: ""
K3S_DATASTORE_ENDPOINT: "mysql://username:password@tcp(hostname:3306)/database-name"
args:
- --node-label ""
- --data-dir ""
# Enabling below it replaces args/env entirely
# replace_env: true
# replace_args: true
k3s-agent:
# Additional env/args for k3s agent instances
env:
K3S_NODE_NAME: "foo"
args:
- --private-registry "..."
# Enabling below it replaces args/env entirely
# replace_env: true
# replace_args: true
# The p2p block enables the p2p full-mesh functionalities.
# To disable, don't specify one.
p2p:
# Manually set node role. Available: master, worker. Defaults auto (none). This is available
role: "master"
# User defined network-id. Can be used to have multiple clusters in the same network
network_id: "dev"
# Enable embedded DNS See also: https://mudler.github.io/edgevpn/docs/concepts/overview/dns/
dns: true
# Disabling DHT makes co-ordination to discover nodes only in the local network
disable_dht: true #Enabled by default
# Configures a VPN for the cluster nodes
vpn:
create: false # defaults to true
use: false # defaults to true
env:
# EdgeVPN environment options
DHCP: "true"
# Disable DHT (for airgap)
EDGEVPNDHT: "false"
EDGEVPNMAXCONNS: "200"
# If DHCP is false, it's required to be given a specific node IP. Can be arbitrary
ADDRESS: "10.2.0.30/24"
# See all EDGEVPN options:
# - https://github.com/mudler/edgevpn/blob/master/cmd/util.go#L33
# - https://github.com/mudler/edgevpn/blob/master/cmd/main.go#L48
# Automatic cluster deployment configuration
auto:
# Enables Automatic node configuration (self-coordination)
# for role assignment
enable: true
# HA enables automatic HA roles assignment.
# A master cluster init is always required,
# Any additional master_node is configured as part of the
# HA control plane.
# If auto is disabled, HA has no effect.
ha:
# Enables HA control-plane
enable: true
# Number of HA additional master nodes.
# A master node is always required for creating the cluster and is implied.
# The setting below adds 2 additional master nodes, for a total of 3.
master_nodes: 2
# Use an External database for the HA control plane
external_db: "external-db-string"
# network_token is the shared secret used by the nodes to co-ordinate with p2p
network_token: "YOUR_TOKEN_GOES_HERE"
## Sets the Elastic IP used in KubeVIP. Only valid with p2p
kubevip:
eip: "192.168.1.110"
# Specify a manifest URL for KubeVIP. Empty uses default
manifest_url: ""
# Enables KubeVIP
enable: true
# Specifies a KubeVIP Interface
interface: "ens18"
# Additional cloud init syntax can be used here.
# See `stages` below.
stages:
network:
- name: "Setup users"
authorized_keys:
kairos:
- github:mudler
# Standard cloud-init syntax, see: https://github.com/mudler/yip/tree/e688612df3b6f24dba8102f63a76e48db49606b2#compatibility-with-cloud-init-format
growpart:
devices: ['/']
runcmd:
- foo
hostname: "bar"
write_files:
- encoding: b64
content: CiMgVGhpcyBmaWxlIGNvbnRyb2xzIHRoZSBzdGF0ZSBvZiBTRUxpbnV4
path: /foo/bar
permissions: "0644"
owner: "bar"
The p2p block is used to enable the p2p full-mesh functionalities of Kairos. If you do not want to use these functionalities, simply don’t specify a kairos block in your configuration file.
Inside the p2p block, you can specify the network_token field, which is used to establish the p2p full meshed network. If you do not want to use the full-mesh functionalities, don’t specify a network_token value.
The role field allows you to manually set the node role for your Kairos installation. The available options are master and worker, and the default value is auto (which means no role is set).
The network_id field allows you to set a user-defined network ID, which can be used to have multiple Kairos clusters on the same network.
Finally, the dns field allows you to enable embedded DNS for Kairos. For more information on DNS in Kairos, see the link provided in the YAML code above.
That’s a brief overview of the structure and fields available in the Kairos configuration file. For more detailed information on how to use these fields, see the examples and explanations provided in the sections below.
Syntax
Kairos supports a portion of the standard cloud-init syntax, and the extended syntax which is based on yip.
Examples using the extended notation for running K3s as agent or server can be found in the examples directory of the Kairos repository.
Here’s an example that shows how to set up DNS at the boot stage using the extended syntax:
#cloud-config
stages:
boot:
- name: "DNS settings"
dns:
path: /etc/resolv.conf
nameservers:
- 8.8.8.8
Note
Kairos does not use cloud-init. yip was created with the goal of being distro agnostic, and does not use Bash at all (with the exception of systemd configurations, which are assumed to be available). This makes it possible to run yip on minimal Linux distros that have been built from scratch.
The rationale behind using yip instead of cloud-init is that it allows Kairos to have very minimal requirements. The cloud-init implementation has dependencies, while yip does not, which keeps the dependency tree small. There is also a CoreOS implementation of cloud-init, but it makes assumptions about the layout of the system that are not always applicable to Kairos, making it less portable.
The extended syntax can also be used to pass commands through Kernel boot parameters. See the examples below for more details.
Test your cloud configs
Writing YAML files can be a tedious process, and it’s easy to make syntax or indentation errors. To make sure your configuration is correct, you can use the cloud-init commands to test your YAML files locally in a container.
Here’s an example of how to test your configurations on the initramfs stage using a Docker container:
# List the YAML files in your current directory
$ ls -liah
total 4,0K
9935 drwxr-xr-x. 2 itxaka itxaka 60 may 17 11:21 .
1 drwxrwxrwt. 31 root root 900 may 17 11:28 ..
9939 -rw-r--r--. 1 itxaka itxaka 59 may 17 11:21 00_test.yaml
$ cat 00_test.yaml
stages:
initramfs:
- commands:
- echo "hello!"
# Run the cloud-init command on your YAML files in a Docker container
$ docker run -ti -v $PWD:/test --entrypoint /usr/bin/kairos-agent --rm quay.io/kairos/opensuse:leap-15.5-core-amd64-generic-v3.0.12 run-stage --cloud-init-paths /test initramfs
# Output from the run-stage command
INFO[2023-05-17T11:32:09+02:00] kairos-agent version 0.0.0
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs.before
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs.before'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs
INFO[2023-05-17T11:32:09+02:00] Processing stage step ''. ( commands: 1, files: 0, ... )
INFO[2023-05-17T11:32:09+02:00] Command output: hello!
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs.after
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs.after'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs.before
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs.before'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs'
INFO[2023-05-17T11:32:09+02:00] Running stage: initramfs.after
INFO[2023-05-17T11:32:09+02:00] Done executing stage 'initramfs.after'
Validate Your Cloud Config
Note
Validation of configuration is available on Kairos v1.6.0-rc1 and later. If you’re interested in the validation rules or want to build a tool based on it, you can access them online viahttps://kairos.io/RELEASE/cloud-config.json e.g. v1.6.0 cloud-config.json
You have two options to validate your Cloud Config, one is with the Kairos command line, and the other with the Web UI.
Configuration Validation via the Kairos Command Line
To validate a configuration using the command line, we have introduced the validate command. As an argument you need to pass a URL or local file to be validated, e.g.:
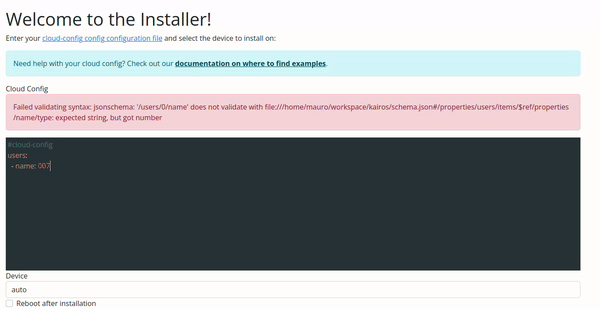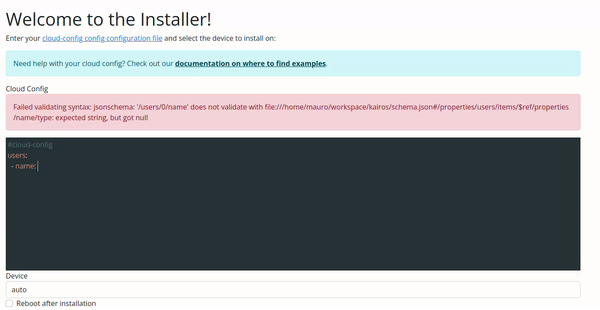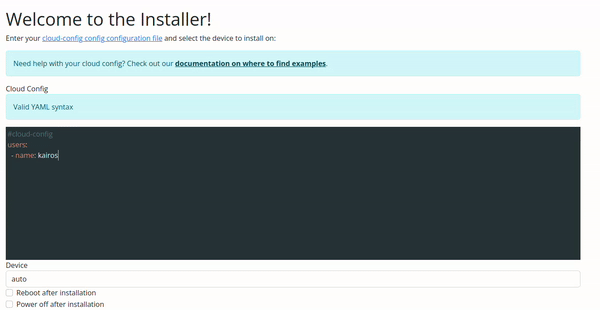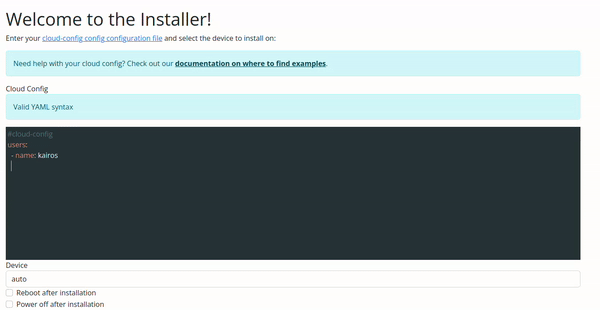
If you had the following cloud-config.yaml in the current working directory
#cloud-config
users:
- name: 007
You could validate it as follows
kairos validate ./cloud-config.yaml
jsonschema: '/users/0/name' does not validate with file:///home/mauro/workspace/kairos/schema.json#/properties/users/items/$ref/properties/name/type: expected string, but got number
Configuration Validation via Web UI
The validation in the Web UI is automatic, all you need to do is copy/paste or type your configuration on the input.
Using templates
Fields in the Kairos cloud-init configuration can be templated, which allows for dynamic configuration. Node information is retrieved using the sysinfo library, and can be templated in the commands, file, and entity fields.
Here’s an example of how you can use templating in your Kairos configuration:
#cloud-config
stages:
foo:
- name: "echo"
commands:
- echo "{{.Values.node.hostname}}"
In addition to standard templating, sprig functions are also available for use in your Kairos configuration.
Automatic Hostname at scale
You can also use templating to automatically generate hostnames for a set of machines. For example, if you have a single cloud-init file that you want to use for multiple machines, you can use the machine ID (which is generated for each host) to automatically set the hostname for each machine.
Here’s an example of how you can do this:
#cloud-config
stages:
initramfs:
- name: "Setup hostname"
hostname: "node-{{ trunc 4 .MachineID }}"
This will set the hostname for each machine based on the first 4 characters of the machine ID. For example, if the machine ID for a particular machine is abcdef123456, the hostname for that machine will be set to node-abcd.
K3s settings
The k3s and k3s-agent blocks in the Kairos configuration file allow you to customize the environment and argument settings for K3s.
Here’s an example of how to use these blocks in your Kairos configuration:
k3s:
enabled: true
# Additional env/args for k3s server instances
env:
K3S_RESOLV_CONF: ""
K3S_DATASTORE_ENDPOINT: ""
args:
- ...
k3s-agent:
enabled: true
# Additional env/args for k3s server instances
env:
K3S_RESOLV_CONF: ""
K3S_DATASTORE_ENDPOINT: ""
args:
-
Warning
The K3s args are only applied when the K3s service is created, which is during installation. Changing theargs key after installation won’t have any effect.
For more examples of how to configure K3s manually, see the examples section or HA.
Grub options
The install.grub_options field in the Kairos configuration file allows you to set key/value pairs for GRUB options that will be set in the GRUB environment after installation.
Here’s an example of how you can use this field to set the panic=0 boot argument:
#cloud-config
install:
grub_options:
extra_cmdline: "panic=0"
The table below lists all the available options for the install.grub_options field:
| Variable | Description |
|---|---|
| next_entry | Set the next reboot entry |
| saved_entry | Set the default boot entry |
| default_menu_entry | Set the name entries on the GRUB menu |
| extra_active_cmdline | Set additional boot commands when booting into active |
| extra_passive_cmdline | Set additional boot commands when booting into passive |
| extra_recovery_cmdline | Set additional boot commands when booting into recovery |
| extra_cmdline | Set additional boot commands for all entries |
| default_fallback | Sets default fallback logic |
Kubernetes manifests
The k3s distribution of Kubernetes allows you to automatically deploy Helm charts or Kubernetes resources after deployment.
Here’s an example of how you can use the k3s configuration file to deploy Fleet out of the box:
name: "Deploy fleet out of the box"
stages:
boot:
- name: "Copy fleet deployment files"
files:
- path: /var/lib/rancher/k3s/server/manifests/fleet-config.yaml
content: |
apiVersion: v1
kind: Namespace
metadata:
name: cattle-system
---
apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata:
name: fleet-crd
namespace: cattle-system
spec:
chart: https://github.com/rancher/fleet/releases/download/v0.3.8/fleet-crd-0.3.8.tgz
---
apiVersion: helm.cattle.io/v1
kind: HelmChart
metadata:
name: fleet
namespace: cattle-system
spec:
chart: https://github.com/rancher/fleet/releases/download/v0.3.8/fleet-0.3.8.tgz
This configuration will automatically deploy the Fleet Helm chart in the cattle-system namespace after the deployment of k3s using the extended syntax.
Kernel boot parameters
All the configurations can be issued via Kernel boot parameters, for instance, consider to add an user from the boot menu:
stages.boot[0].authorized_keys.root[0]=github:mudler
Or to either load a config url from network:
config_url=http://...
Usually secret gists are used to share such config files.
Additional users
Kairos comes with the kairos user pre-configured, however, it is possible to configure additional users to the system via the cloud-init config mechanism
Add a user during first-install
Consider the following example cloud-config, which adds the testuser user to the system with admin access:
#cloud-config
install:
device: /dev/sda
k3s:
enabled: true
users:
- name: "kairos"
passwd: "kairos"
ssh_authorized_keys:
- github:mudler
- name: "testuser"
passwd: "testuser"
ssh_authorized_keys:
- github:mudler
groups:
- "admin"
Add a user to an existing install
To add an user to an existing installation you can simply add a /oem file for the new user. For instance, consider the following:
stages:
initramfs:
- name: "Set user and password"
users:
testuser:
groups:
- "admin"
passwd: "mypassword"
shell: /bin/bash
homedir: "/home/testuser"
This configuration can be either manually copied over, or can be propagated also via Kubernetes using the system upgrade controller. See the after-install section for an example.
❯ ssh testuser@192.168.1.238
testuser@192.168.1.238's password:
Welcome to kairos!
Refer to https://kairos.io for documentation.
localhost:~$ sudo su -
localhost:~# whoami
root
localhost:~# exit
localhost:~$ whoami
testuser
localhost:~$
P2P configuration
P2P functionalities are experimental Kairos features and disabled by default. In order to enable them, just use the p2p configuration block.
p2p.network_token
This defines the network token used by peers to join the p2p virtual private network. You can generate it with the Kairos CLI with kairos generate-token. Check out the P2P section for more instructions.
p2p.role
Define a role for the node. Accepted: worker, master. Currently only one master is supported.
p2p.network_id
Define a custom ID for the Kubernetes cluster. This can be used to create multiple clusters in the same network segment by specifying the same id across nodes with the same network token. Accepted: any string.
p2p.dns
When the p2p.dns is set to true the embedded DNS is configured on the node. This allows to propagate custom records to the nodes by using the blockchain DNS server. For example, this is assuming kairosctl bridge is running in a separate terminal:
curl -X POST http://localhost:8080/api/dns --header "Content-Type: application/json" -d '{ "Regex": "foo.bar", "Records": { "A": "2.2.2.2" } }'
It will add the foo.bar domain with 2.2.2.2 as A response.
Every node with DNS enabled will be able to resolve the domain after the domain is correctly announced.
You can check out the DNS in the DNS page in the API, see also the EdgeVPN docs.
Furthermore, it is possible to tweak the DNS server which are used to forward requests for domain listed outside, and as well, it’s possible to lock down resolving only to nodes in the blockchain, by customizing the configuration file:
#cloud-config
p2p:
network_token: "...."
# Enable embedded DNS See also: https://mudler.github.io/edgevpn/docs/concepts/overview/dns/
dns: true
vpn:
env:
# Disable DNS forwarding
DNSFORWARD: "false"
# Set cache size
DNSCACHESIZE: "200"
# Set DNS forward server
DNSFORWARDSERVER: "8.8.8.8:53"
Stages
The stages key is a map that allows to execute blocks of cloud-init directives during the lifecycle of the node stages.
A full example of a stage is the following:
#cloud-config
stages:
# "boot" is the stage
boot:
- systemd_firstboot:
keymap: us
- files:
- path: /tmp/bar
content: |
test
permissions: 0777
owner: 1000
group: 100
if: "[ ! -e /tmp/bar ]"
- files:
- path: /tmp/foo
content: |
test
permissions: 0777
owner: 1000
group: 100
commands:
- echo "test"
modules:
- nvidia
environment:
FOO: "bar"
systctl:
debug.exception-trace: "0"
hostname: "foo"
systemctl:
enable:
- foo
disable:
- bar
start:
- baz
mask:
- foobar
authorized_keys:
user:
- "github:mudler"
- "ssh-rsa ...."
dns:
path: /etc/resolv.conf
nameservers:
- 8.8.8.8
ensure_entities:
- path: /etc/passwd
entity: |
kind: "user"
username: "foo"
password: "pass"
uid: 0
gid: 0
info: "Foo!"
homedir: "/home/foo"
shell: "/bin/bash"
delete_entities:
- path: /etc/passwd
entity: |
kind: "user"
username: "foo"
password: "pass"
uid: 0
gid: 0
info: "Foo!"
homedir: "/home/foo"
shell: "/bin/bash"
datasource:
providers:
- "digitalocean"
- "aws"
- "gcp"
path: "/usr/local/etc"
Note multiple stages can be specified, to execute blocks into different stages, consider:
#cloud-config
stages:
boot:
- commands:
- echo "hello from the boot stage"
initramfs:
- commands:
- echo "hello from the boot stage"
- commands:
- echo "so much wow, /foo/bar bar exists!"
if: "[ -e /foo/bar ]"
Below you can find a list of all the supported fields. Mind to replace with the appropriate stage you want to hook into.
Filtering stages by node hostname
Stages can be filtered using the node key with a hostname value:
#cloud-config
stages:
foo:
- name: "echo"
commands:
- echo hello
node: "the_node_hostname_here" # Node hostname
Filtering stages with if statement
Stages can be skipped based on if statements:
#cloud-config
stages:
foo:
- name: "echo"
commands:
- echo hello
if: "cat /proc/cmdline | grep debug"
name: "Test yip!"
The expression inside the if will be evaluated in bash and, if specified, the stage gets executed only if the condition returns successfully (exit 0).
name
A description of the stage step. Used only when printing output to console.
commands
A list of arbitrary commands to run after file writes and directory creation.
#cloud-config
stages:
boot:
- name: "Setup something"
commands:
- echo 1 > /bar
files
A list of files to write to disk.
#cloud-config
stages:
boot:
- files:
- path: /tmp/bar
content: |
#!/bin/sh
echo "test"
permissions: 0777
owner: 1000
group: 100
directories
A list of directories to be created on disk. Runs before files.
#cloud-config
stages:
boot:
- name: "Setup folders"
directories:
- path: "/etc/foo"
permissions: 0600
owner: 0
group: 0
dns
A way to configure the /etc/resolv.conf file.
#cloud-config
stages:
boot:
- name: "Setup dns"
dns:
nameservers:
- 8.8.8.8
- 1.1.1.1
search:
- foo.bar
options:
- ..
path: "/etc/resolv.conf.bak"
hostname
A string representing the machine hostname. It sets it in the running system, updates /etc/hostname and adds the new hostname to /etc/hosts.
Templates can be used to allow dynamic configuration. For example in mass-install scenario it could be needed (and easier) to specify hostnames for multiple machines from a single cloud-init config file.
#cloud-config
stages:
boot:
- name: "Setup hostname"
hostname: "node-{{ trunc 4 .MachineID }}"
sysctl
Kernel configuration. It sets /proc/sys/<key> accordingly, similarly to sysctl.
#cloud-config
stages:
boot:
- name: "Setup exception trace"
systctl:
debug.exception-trace: "0"
authorized_keys
A list of SSH authorized keys that should be added for each user. SSH keys can be obtained from GitHub user accounts by using the format github:${USERNAME}, similarly for GitLab with gitlab:${USERNAME}.
#cloud-config
stages:
boot:
- name: "Setup exception trace"
authorized_keys:
mudler:
- "github:mudler"
- "ssh-rsa: ..."
node
If defined, the node hostname where this stage has to run, otherwise it skips the execution. The node can also be a regexp in the Golang format.
#cloud-config
stages:
boot:
- name: "Setup logging"
node: "bastion"
users
A map of users and user info to set. Passwords can also be encrypted.
The users parameter adds or modifies the specified list of users. Each user is an object which consists of the following fields. Each field is optional and of type string unless otherwise noted.
In case the user already exists, only the password and ssh-authorized-keys are evaluated. The rest of the fields are ignored.
- name: Required. Login name of user
- gecos: GECOS comment of user
- passwd: Hash of the password to use for this user. Unencrypted strings are supported too.
- homedir: User’s home directory. Defaults to /home/name
- no-create-home: Boolean. Skip home directory creation.
- primary-group: Default group for the user. Defaults to a new group created named after the user.
- groups: Add user to these additional groups
- no-user-group: Boolean. Skip default group creation.
- ssh-authorized-keys: List of public SSH keys to authorize for this user
- system: Create the user as a system user. No home directory will be created.
- no-log-init: Boolean. Skip initialization of lastlog and faillog databases.
- shell: User’s login shell.
#cloud-config
stages:
boot:
- name: "Setup users"
users:
bastion:
passwd: "strongpassword"
homedir: "/home/foo
ensure_entities
A user or a group in the entity format to be configured in the system
#cloud-config
stages:
boot:
- name: "Setup users"
ensure_entities:
- path: /etc/passwd
entity: |
kind: "user"
username: "foo"
password: "x"
uid: 0
gid: 0
info: "Foo!"
homedir: "/home/foo"
shell: "/bin/bash"
delete_entities
A user or a group in the entity format to be pruned from the system
#cloud-config
stages:
boot:
- name: "Setup users"
delete_entities:
- path: /etc/passwd
entity: |
kind: "user"
username: "foo"
password: "x"
uid: 0
gid: 0
info: "Foo!"
homedir: "/home/foo"
shell: "/bin/bash"
modules
A list of kernel modules to load.
#cloud-config
stages:
boot:
- name: "Setup users"
modules:
- nvidia
systemctl
A list of systemd services to enable, disable, mask or start.
#cloud-config
stages:
boot:
- name: "Setup users"
systemctl:
enable:
- systemd-timesyncd
- cronie
mask:
- purge-kernels
disable:
- crond
start:
- cronie
environment
A map of variables to write in /etc/environment, or otherwise specified in environment_file
#cloud-config
stages:
boot:
- name: "Setup users"
environment:
FOO: "bar"
environment_file
A string to specify where to set the environment file
#cloud-config
stages:
boot:
- name: "Setup users"
environment_file: "/home/user/.envrc"
environment:
FOO: "bar"
timesyncd
Sets the systemd-timesyncd daemon file (/etc/system/timesyncd.conf) file accordingly. The documentation for timesyncd and all the options can be found here.
#cloud-config
stages:
boot:
- name: "Setup NTP"
systemctl:
enable:
- systemd-timesyncd
timesyncd:
NTP: "0.pool.org foo.pool.org"
FallbackNTP: ""
...
datasource
Sets to fetch user data from the specified cloud providers. It populates
provider specific data into /run/config folder and the custom user data
is stored into the provided path.
#cloud-config
stages:
boot:
- name: "Fetch cloud provider's user data"
datasource:
providers:
- "aws"
- "digitalocean"
path: "/etc/cloud-data"
layout
Sets additional partitions on disk free space, if any, and/or expands the last
partition. All sizes are expressed in MiB only and default value of size: 0
means all available free space in disk. This plugin is useful to be used in
oem images where the default partitions might not suit the actual disk geometry.
#cloud-config
stages:
boot:
- name: "Repart disk"
layout:
device:
# It will partition a device including the given filesystem label
# or partition label (filesystem label matches first) or the device
# provided in 'path'. The label check has precedence over path when
# both are provided.
label: "COS_RECOVERY"
path: "/dev/sda"
# Only last partition can be expanded and it happens after all the other
# partitions are created. size: 0 means all available free space
expand_partition:
size: 4096
add_partitions:
- fsLabel: "COS_STATE"
size: 8192
# No partition label is applied if omitted
pLabel: "state"
- fsLabel: "COS_PERSISTENT"
# default filesystem is ext2 if omitted
filesystem: "ext4"
You can also set custom partitions within the kairos-install.pre.before stage. In the following example we will do a
custom partition in disk /dev/vda.
Warning
You’re responsible to make sure the sizes of the partitions fit properly within the disk. Issues of space will be highlighted by the agent, but they will not fail the installation process unless you pass the--strict flag.
Warning
In the case of multiple devices, make sure you don’t chooseauto to determine on which device to install but instead to point
the installation to the device where you are creating the custom partitions.
#cloud-config
install:
# Make sure the installer won't delete our custom partitions
no-format: true
stages:
kairos-install.pre.before:
- if: '[ -e /dev/vda ]'
name: "Create partitions"
commands:
- |
parted --script --machine -- /dev/vda mklabel msdos
layout:
device:
path: /dev/vda
expand_partition:
size: 0 # All available space
add_partitions:
# all sizes bellow are in MB
- fsLabel: COS_OEM
size: 64
pLabel: oem
- fsLabel: COS_RECOVERY
size: 8500
pLabel: recovery
- fsLabel: COS_STATE
size: 18000
pLabel: state
- fsLabel: COS_PERSISTENT
pLabel: persistent
size: 25000
filesystem: "ext4"
git
Pull git repositories, using golang native git (no need of git in the host).
#cloud-config
stages:
boot:
- git:
url: "git@gitlab.com:.....git"
path: "/oem/cloud-config-files"
branch: "main"
auth:
insecure: true
private_key: |
-----BEGIN RSA PRIVATE KEY-----
-----END RSA PRIVATE KEY-----
downloads
Download files to specified locations
#cloud-config
stages:
boot:
- downloads:
- path: /tmp/out
url: "https://www...."
permissions: 0700
owner: 0
group: 0
timeout: 0
owner_string: "root"
- path: /tmp/out
url: "https://www...."
permissions: 0700
owner: 0
group: 0
timeout: 0
owner_string: "root"
Feedback
Was this page helpful?
Awesome! Glad to hear it! Please tell us how we can improve.
Oh snap! Sorry to hear that. Please tell us how we can improve.